Otra de las cosas que se comentaron en la última reunión era que ya tenemos una primera fecha “límite:
En ella deberemos de ser capaces de contar todo nuestro trabajo en 10 min y en Inglés. En este magnífico congreso. Para ello contaremos tb con una presentación (powerpoint) que resumirá todo nuestro trabajo. Tb deberemos realizar un poster para esas fechas…
Pero…, para contar nuestro trabajo, primero debemos de ordenarlo de manera escrita. Os recomiendo que le echéis un vistazo en recursos a los trabajos previos, sobre todo al del año pasado que se titulaba: “Bioinformatic analysis of specific groups of prokaryotic reverse-transcriptases”.
Debemos de ser capaces, de momento de escribir algo parecido… Pero, este año hemos llegado más lejos… . De hecho ya podemos ir pensando en un posible título, aunque esto lo tendremos que discutir en una reunión…
Todo trabajo debe de tener:
Resumen, Introducción, Material y Métodos, Resultados, Discusión y Conclusiones. A su vez estos trabajos tienen un apartado de “my own ideas” donde tendréis que hacer una lectura más personal de lo que habéis hecho. Sabiendo además que lo que tenéis que escribir forma parte tb de vuestro “proyecto” en el Instituto para el curso que viene (40 pgs o así), podemos plantear en él también una estructura similar.
Por el momento deberéis centraros en los apartados M y Métodos y Resultados. Saber qué vamos a contar en estos apartados definirá posteriormente la Introducción. Para la Introducción tendré que ayudaros y guiaros más en detalle. Podéis ir viendo las primeras presentaciones; son la verdadera introducción de donde nos hemos metido. Estos tres apartados definirán subsiguientemente los Objetivos del trabajo que no son necesariamente iguales a los que teníamos planteados “Definiendo y estudiando ‘retrones’” pero que no andarán muy lejos. El Resumen y la Discusión se abordarán cuando estos apartados estén ya definidos y casi completos.
A modo de ejemplo y para empezar, en Mat y Meth. Debemos de explicar:
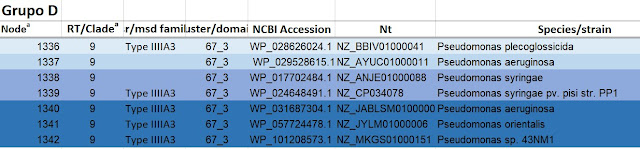
Como Material: Las secuencias con las que hemos trabajado (de donde provienen. Habrá que añadir una tabla).
-El programa clone manager. Que hace, que interpreta, como trabaja…
-los programas de busqueda, blast… creo que los hemos usado tb…
-los programas de la universidad de Viena RNA web services (RNA fold y RNAalifold).
-Si terminamos usando el varna, habrá que ponerlo tb (de momento no es seguro)
Por supuesto, en todo momento hay que tener en cuenta la bibliografía… Dos trabajos van a ser sin duda referidos:
- Simon AJ, Ellington AD, Finkelstein IJ. Retrons and their applications in genome engineering. Nucleic Acids Res. 2019. 47:11007-11019. Donde describen de una manera muy actual qué es un retron.
- Mestre MR, González-Delgado A, Gutiérrez-Rus LI, Martínez-Abarca F, Toro N. Systematic prediction of genes functionally associated with bacterial retrons and classification of the encoded tripartite systems. Nucleic Acids Res. 2020. 48:12632-12647. Donde se describe el sistema de retrones tipo III-A3 en el que hemos trabajado.
Os recomiendo de nuevo que le hagáis un buen vistazo al blog desde el principio hasta hoy y os daréis cuenta de todo el camino recorrido y será una buena manera de ver como lo resumimos y contamos!!!! Y como siempre soy todo oídos, bien por aquí, bien por el mail, bien a través de vuestro profesor Javier.
Ánimo!! Ya se vislumbra el fin de nuestro trabajazo!!!!!