El pasado Viernes comenzamos a vislumbrar en lo que va a consistir nuestro proyecto:
“Analizar y entender la información que “esconde” una secuencia de ADN”.
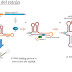
Para ello hemos aprendido que el DNA está constituido por dos hebras… esto lo hemos puesto de manifiesto con diversas herramientas del programa…


Fig. 2 Sentido y antisentido en toda cadena de DNA. EL ADN tiene una dirección 5’ - - - - > 3’
 |
Fig 3. La herramienta ‘compare’
Y su diferencia con la herramienta ‘align’; La herramienta ORFsearch ….
Ufffffffff!!!! Qué rápido va nuestro investigador!!!!!
Tendremos nuevas sesiones donde afianzar este manejo… y poco a poco empezar con el análisis de “nuestras secuencias”…
De nuevo sería bueno revisar los tutoriales del programa en el blog del año pasado: https://sites.google.com/view/caosdna/recursos/Recursos?authuser=0
Seguro que ahora los entendemos mejor!!!
Dr Francisco Martinez-Abarca
Estacion Experimental del Zaidin - CSIC
Department of Microbiology
C/ Profesor Albareda n 1
18008 Granada
Spain



Qué buen comienzo!
ResponderEliminarMaría for president!
Poco a poco vamos entendiendo algo!!
ResponderEliminarJajajajajaja, mis explicaciones son lo mejor👏🏼😅
ResponderEliminarLos comienzos son siempre complicadillos. Pero creedme en breve iremos mucho más rapido y ya con preguntas reales sobre nuestro proyecto.... Aupa DNA team!!!
ResponderEliminarFco Mtez-Abarca